Интересная и полезная статья — результат десятков прочитанных материалов: статей, мануалов, просмотренных видео, а также множества тестов и практики. Но что делать, если времени совсем нет? Ответ прост: использовать современные инструменты и системы автоматизации, такие как n8n.
Мы подготовили цикл статей с рецептом современного стека автоматизации на базе n8n для запуска в продакшен Telegram-бота, который читает статьи и делает краткое саммари, чтобы можно было быстро понять, нужно ли тратить время на статью.
Ссылки на исходники проекта мы дадим сразу. С кодом перед глазами материал будет восприниматься проще и целостнее. Скачать исходный код проекта можно с этого репозитория, а этот репозиторий содержит наши готовые n8n workflows.
Пробовать запускать проект можно уже после прочтения первой статьи цикла, в которой содержится:
- Логика работы проекта.
- Инструменты и ресурсы запуска проекта.
- Создание Telegram-бота.
Надеемся, что вы готовы к погружению в мир автоматизации, бэкенда и современных AI-чудес.
Логика работы проекта
Сначала приведем общую логическую схему работы нашего проекта — так станет понятно, за что отвечает каждый элемент. Дальше будем переходить к более низким слоям реализации. Логическая схема работы проекта выглядит следующим образом:
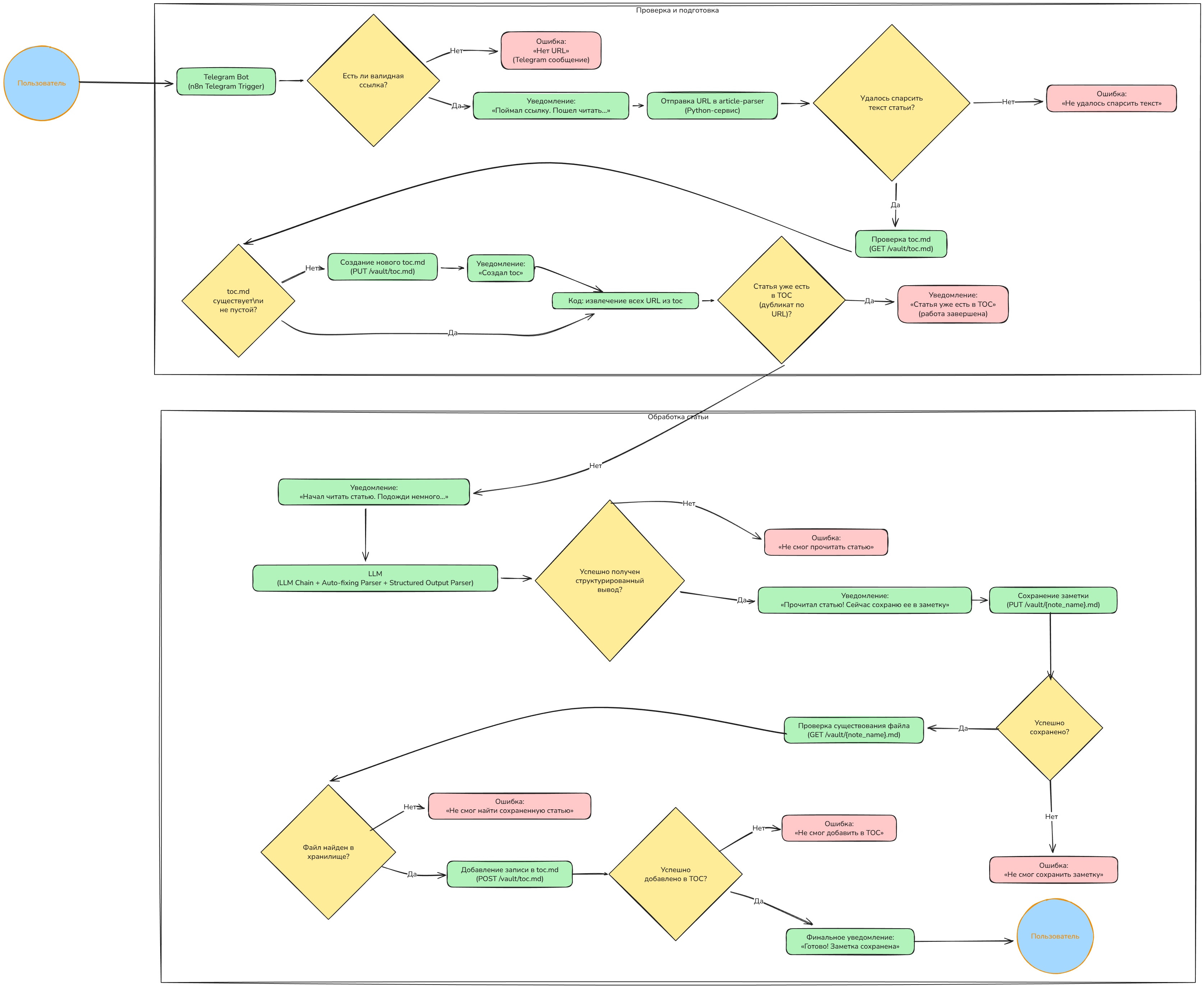
Вся логика автоматизации выполняется в n8n — в основном на нодах Telegram, HTTP Request и IF. Малая часть процесса автоматизации вынесена в отдельный Python-микросервис (article-parser), который принимает ссылку на статью и подготавливает текст статьи для AI-агента, удаляя лишний HTML-код. Такое решение экономит токены при работе AI и снижает вероятность ошибок при обработке входного материала, так как на вход AI поступает простой текст, а не HTML-код.
Мозг нашего проекта — это LLM (deepseek-r1:1.5b), которую мы используем через специальную AI-ноду n8n. Нода по API обращается к Ollama и передает запрос в deepseek-r1:1.5b. Результат выполнения запроса возвращается в AI-ноду и передается дальше по workflow.
Детальная пошаговая схема работы workflow выглядит так:
- Пользователь отправляет в Telegram-бот сообщение со ссылкой на статью.
- В n8n срабатывает Telegram Trigger на новое сообщение и происходит извлечение валидной ссылки. Если ссылки в сообщении нет, бот отправляет сообщение об ошибке с текстом «Нет URL», и процесс завершается. Если в сообщении от пользователя есть валидная ссылка на статью — бот отправляет уведомление: «Поймал ссылку. Пошел читать…».
- Ссылка на статью отправляется в микросервис article-parser. Сервис использует библиотеки requests, readability и bs4 для извлечения чистого текста статьи по ссылке, а API к сервису предоставляет Flask. Если текст статьи не удается извлечь — бот отправит сообщение с ошибкой: «Не удалось спарсить текст» и завершит работу.
- Проверка существования файла toc.md (оглавление/список заметок) в Obsidian (GET-запрос через HTTP Request-ноду и Caddy). Если toc.md отсутствует или он пустой — создается новый toc.md с заголовком, а бот отправляет уведомление: «Создал toc».
- Проверка ссылки на дубликат в toc.md. Нода выполнения JS-кода извлекает из toc.md все ссылки и ищет среди них совпадение со ссылкой, присланной пользователем в бот. Если совпадение есть, то бот вернет сообщение в Telegram: «Статья уже есть в TOC» и завершит работу. Если совпадений нет — продолжит работу и сообщит пользователю: «Начал читать статью. Подожди немного…».
- Чтение статьи AI-агентом (Basic LLM chain). Модель переводит (если нужно), анализирует и формирует заметку на русском в Markdown. Используются инструменты Auto-fixing Parser и Structured Output Parser для строгого JSON-формата выходных данных AI-агента. Если модель не смогла сформировать корректный вывод, пользователю будет отправлено сообщение: «Не смог прочитать статью» и работа workflow будет завершена. Если модель смогла сформировать текст заметки — пользователю будет направлено сообщение: «Прочитал статью! Сейчас сохраню ее в заметку».
- Сохранение заметки в Obsidian. HTTP Request-нода выполняет PUT-запрос через Caddy (reverse proxy server) к эндпоинту https://caddy/obsidian/vault/{{ $('Reader').item.json.output.note_name }}.md с содержимым заметки. Если сохранение не удалось, пользователю будет отправлено сообщение с текстом: «Не смог сохранить заметку».
- Проверка успешного сохранения заметки в Obsidian. HTTP Request-нода выполняет GET-запрос к эндпоинту https://caddy/obsidian/vault/{{ $('Reader').item.json.output.note_name }}.md, чтобы прочитать только что созданную заметку. Если файл не найден, пользователю будет отправлено сообщение с текстом ошибки: «Не смог найти сохраненную статью». Работа workflow будет завершена.
- Добавление записи в toc.md. HTTP Request-нода выполняет POST-запрос (append) к эндпоинту https://caddy/obsidian/vault/toc.md со строкой: File name: {note_name}; Link: {оригинальная ссылка}. Если добавление строки не удалось, пользователю будет направлено сообщение: «Не смог добавить в TOC».
- Финальное уведомление пользователя. При успешном выполнении workflow пользователю будет направлено сообщение: «Готово! Заметка “{note_name}” сохранена в Obsidian».
В двух словах логика работы проекта следующая: пользователь отправляет сообщение с URL на статью, Python-микросервис очищает статью от лишнего HTML-кода, затем чистый текст передается в AI-агента, который его читает и подготавливает саммари. После этого саммари сохраняется в виде заметки в Obsidian. В целях отладки и удобства пользователю на каждом шаге выполнения workflow отправляются сообщения со статусами работы автоматизации.
Инструменты и ресурсы запуска проекта
Для запуска проекта понадобится домен и VPS с установленным на нем Docker. Далее мы расскажем о требованиях к VPS, ОС и об инструментах, с которыми будем работать.
DNS и домен
Мы запускаем продакшен-версию бота, и без домена не обойтись. Если у вас уже есть домен — отлично, остается только добавить субдомены и A-записи к ним. А если у вас нет своего домена, то приобрести его можно на GoDaddy или NameCheap.
При покупке домена нужно знать, что есть доменные зоны с низким уровнем доверия, например: .online, .xyz, .site. Домены в таких зонах стоят дешево, но в ряде кейсов бесполезны. Например, при хостинге почты в доменных зонах .online, .xyz, .site — письма будут попадать в спам почти всегда. Также могут быть проблемы с выпуском SSL-сертификатов. Для нашего проекта подойдет любой домен.
Для корректной работы проекта у домена должны быть следующие субдомены с A-записями, в которых указан IP-адрес вашего VPS, где развернут проект: n8n, obsidian, notes, ollama, netdata.
После добавления A-записей в DNS можно переходить в директорию проекта и внести изменения в файл .env, где содержатся параметры SERVER_IP и DOMAIN. Настройки редиректов находятся в соседнем файле Caddyfile.template на случай, если есть необходимость изменить названия субдоменов или добавить что-то новое в стек.
Инструменты
Главным файлом нашего проекта является compose-файл. Он описывает сервисы, необходимые для работы проекта. Однако нужны и дополнительные инструменты, многие из которых уже давно стали де-факто стандартом индустрии:
- n8n — современный low-code фреймворк для автоматизации процессов, использующий node-based подход, при котором основным логическим блоком является нода.
- LLM — большая языковая модель. Будет выбор: использовать локальную LLM через Ollama или проприетарную модель по API.
- BotFather — бот в Telegram для создания и управления ботами.
- Obsidian — менеджер заметок, который хранит тексты в формате Markdown локально в логических хранилищах (vault). Также Obsidian умеет строить граф знаний, поддерживает теги, шаблоны, мощный поиск, плагины и автоматизацию.
- Docker Compose — инструмент для описания и запуска многоконтейнерных приложений Docker с помощью файла compose.yaml.
- Git и GitHub — система контроля версий и хостинг для репозиториев.
Если какой-то из инструментов вам незнаком — загляните к нам в базу знаний: скорее всего, там вы найдете нужную информацию, подсказку или подробный гайд по использованию. Так, например, в нашей базе знаний есть раздел по работе с Docker с подробным разбором команд и приемов.
VPS и ОС
Выбор VPS для развертывания стека зависит от того, будет ли LLM запускаться локально или на стороне LLM-провайдера. Если LLM будет запускаться локально на VPS, тогда понадобятся следующие ресурсы: 8 CPU-ядер, от 16 GB RAM, 200+ GB SSD. Можно сэкономить ресурсы ВМ, если использовать LLM через API (например, Gemini от Google): тогда достаточно будет маломощной ВМ — 4 CPU-ядра, 8 GB RAM, 100 GB SSD.
Выбор конфигурации ВМ в большей степени зависит от последующего использования развернутого стека. Если есть планы в будущем переиспользовать наработки для работы с конфиденциальной информацией, то, конечно же, следует использовать локальную LLM — и тут без мощного VPS будет сложно.
Подобрать оптимальную ВМ для запуска локальных LLM поможет наша статья. В ней же вы найдете полезные советы и инструкции по работе с Ollama — фреймворком, который позволяет запускать LLM локально и управлять ими. А если у вас еще нет VPS нужной конфигурации, загляните в раздел VPS/VDS — уверены, что вы найдете нужную конфигурацию ВМ.
Если с конфигурацией VPS есть вариативность, то требования к ОС строги — лучше всего использовать актуальные версии Ubuntu или Debian. В статье мы используем Ubuntu 24.04.
Итак, зафиксировали: мы разрабатываем Telegram-бота, который читает статьи и сохраняет короткое саммари в Obsidian. За автоматизацию отвечает n8n, а наш стек будет развернут на VPS с локально запущенной LLM через Ollama.
Создание Telegram-бота
На самом деле Telegram-бот — это просто удобный инструмент обращения к бэкенду, где выполняется вся логика работы. Строго говоря, Telegram-бот выполняет роль чата, в котором могут быть заранее преднастроены элементы управления: кнопки и команды. При этом вся бизнес-логика работает на бэкенде. Именно поэтому Telegram-боты так популярны и могут решать почти любые задачи.
На самом деле Telegram-бот — это просто удобный инструмент обращения к бэкенду, где выполняется вся логика работы. Строго говоря, Telegram-бот выполняет роль чата, в котором могут быть заранее преднастроены элементы управления: кнопки и команды. При этом вся бизнес-логика работает на бэкенде. Именно поэтому Telegram-боты так популярны и могут решать почти любые задачи.
Приведем краткую инструкцию создания Telegram-бота для нашего проекта.
1. Откройте Telegram и введите в поиск BotFather.
2. Нажмите на кнопку Открыть/Open.
3. В открывшемся окне нажмите на кнопку Create New Bot.
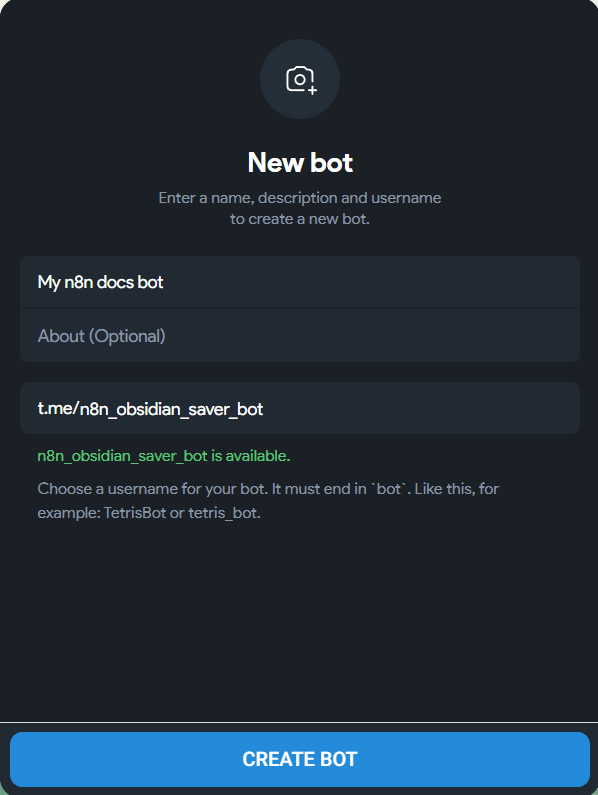
4. Настройте нового бота следующим образом:
- Поле Bot Name — укажите любое понятное вам название
- Поле About — укажите описание бота (можно оставить пустым)
- Поле t.me/username_bot — имя бота, по которому он будет доступен в Telegram. Важно, чтобы имя заканчивалось на _bot. Например, n8n_obsidian_saver_bot
5. Скопируйте токен (API-ключ) бота. Будьте внимательны: кнопка Copy не всегда работает корректно. Чтобы проверить, что ключ скопирован правильно, вставьте токен в любой текстовый редактор или в адресную строку браузера. Если вы увидите строку формата 784324329:EETRNJU3jQEGWQdjNv3llb4bnDSDREGuuuL, значит токен скопирован.
Если в буфере окажутся другие данные, вернитесь в окно с токеном, нажмите на строку токена (чтобы он стал читаемым) и скопируйте его вручную. В крайнем случае можно открыть окно печати и скопировать токен оттуда (обычно это работает через Ctrl + P).
Если в буфере окажутся другие данные, вернитесь в окно с токеном, нажмите на строку токена (чтобы он стал читаемым) и скопируйте его вручную. В крайнем случае можно открыть окно печати и скопировать токен оттуда (обычно это работает через Ctrl + P).
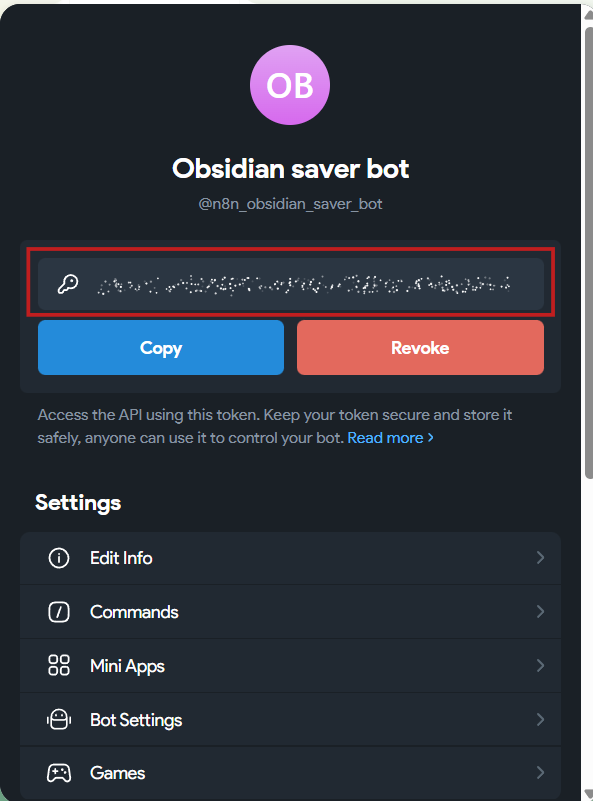
Полученный токен нужно сохранить в Credentials.
Сохранение токена API-ключа Telegram-бота в n8n
Чтобы сохранить токен и в дальнейшем его переиспользовать, нужно выполнить несколько шагов.
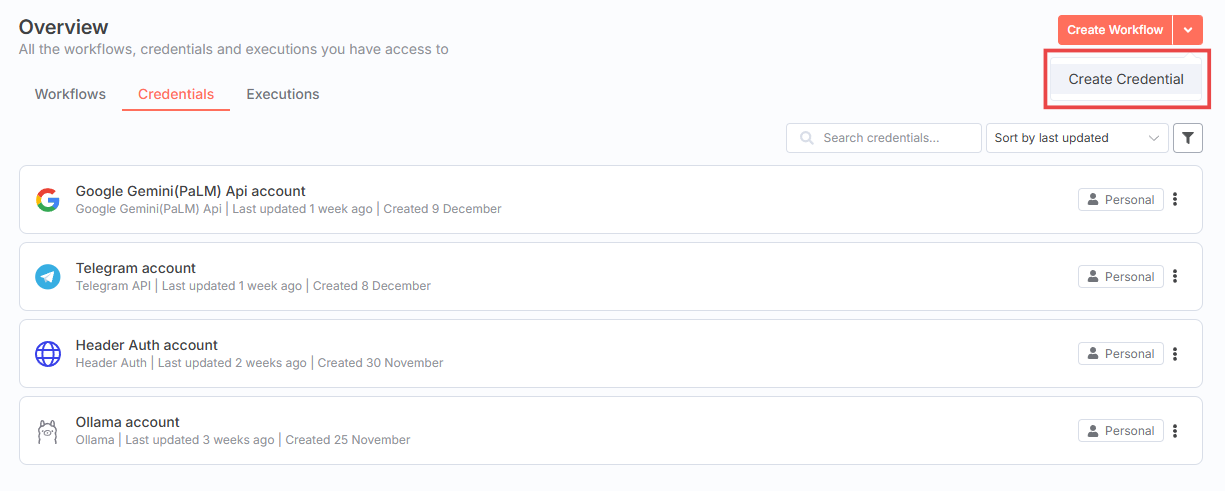
1. Перейдите в раздел Credentials и нажмите в правом верхнем углу кнопку Create Credential (кнопка скрыта в выпадающем меню).
2. Начните вводить в поле Telegram и из предложенных вариантов выберите Telegram API.
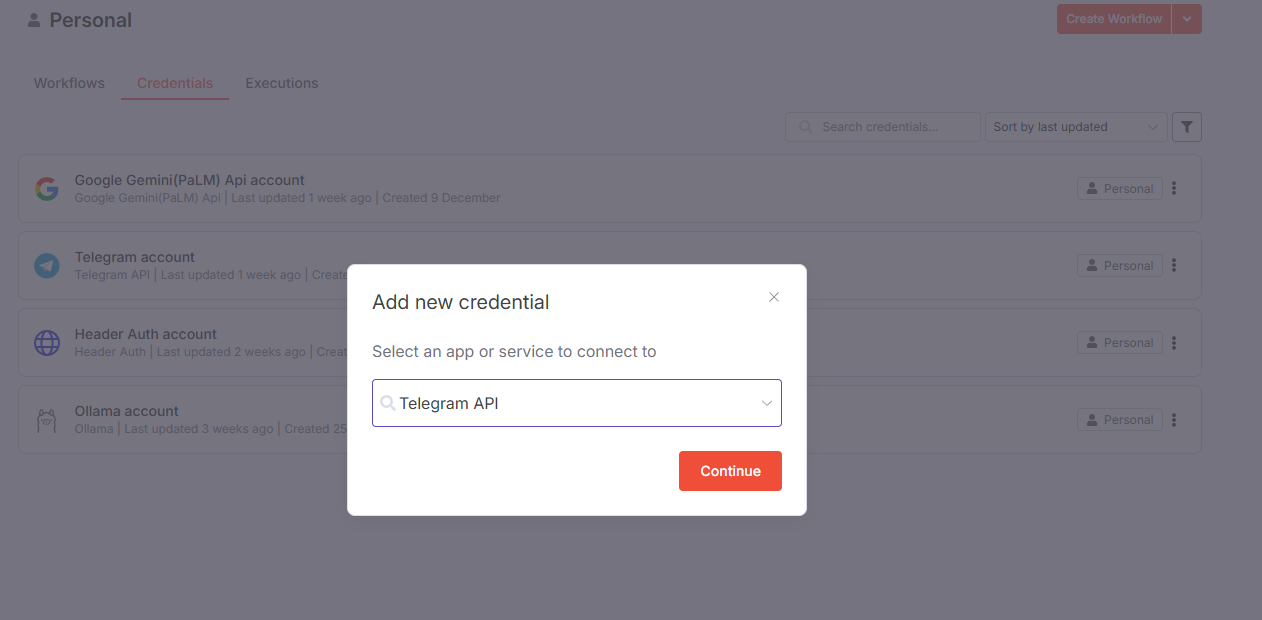
3. Вставьте полученный ранее токен в поле Access Token и нажмите кнопку Save.
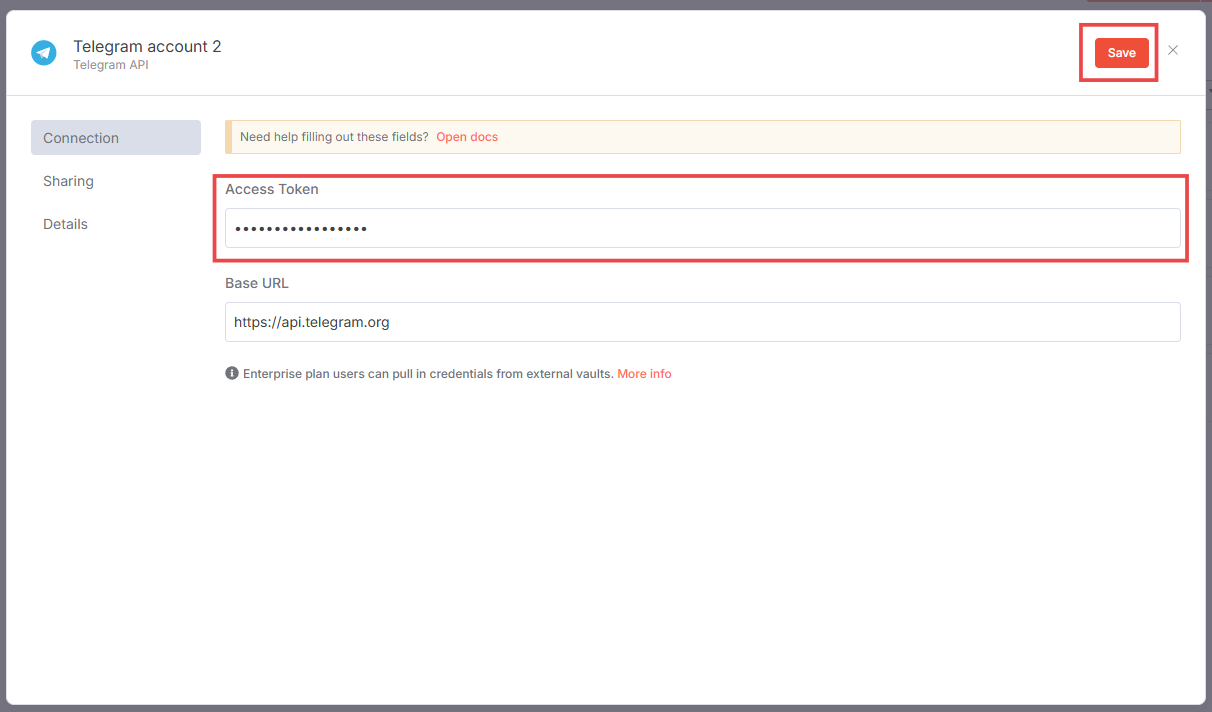
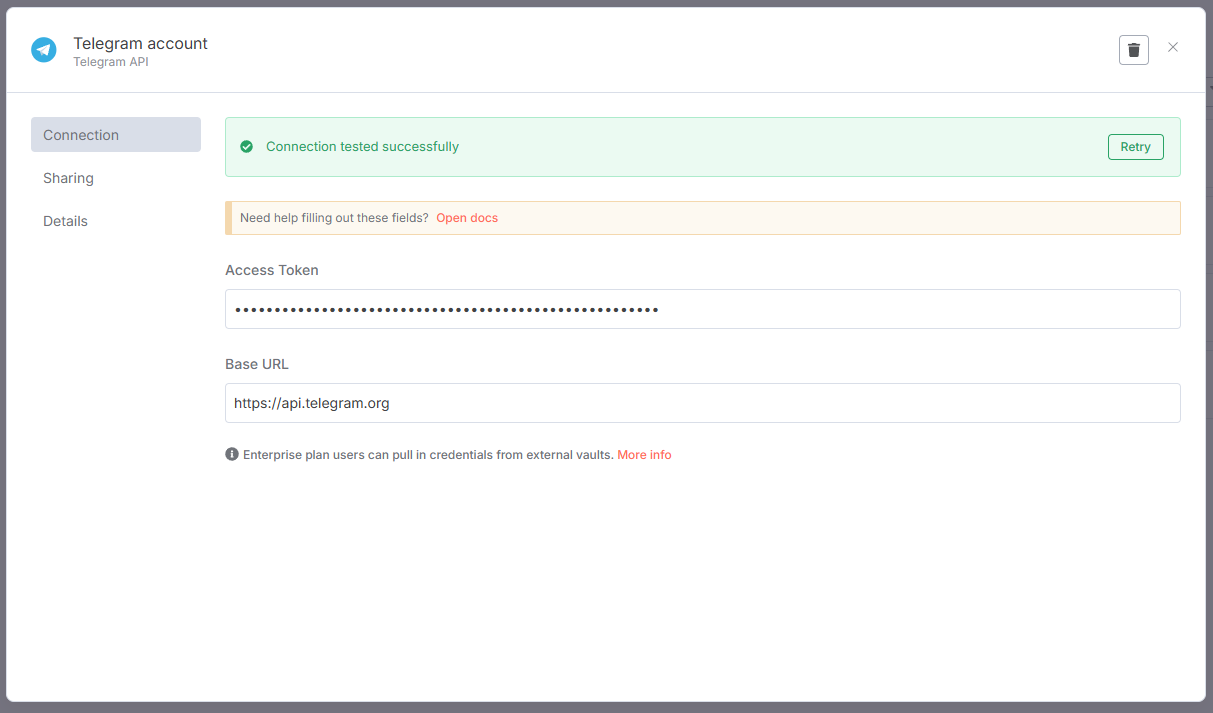
Если токен был скопирован и вставлен правильно — появится сообщение: Connection tested successfully.
Если токен неправильный — появится сообщение: Couldn’t connect with these settings.
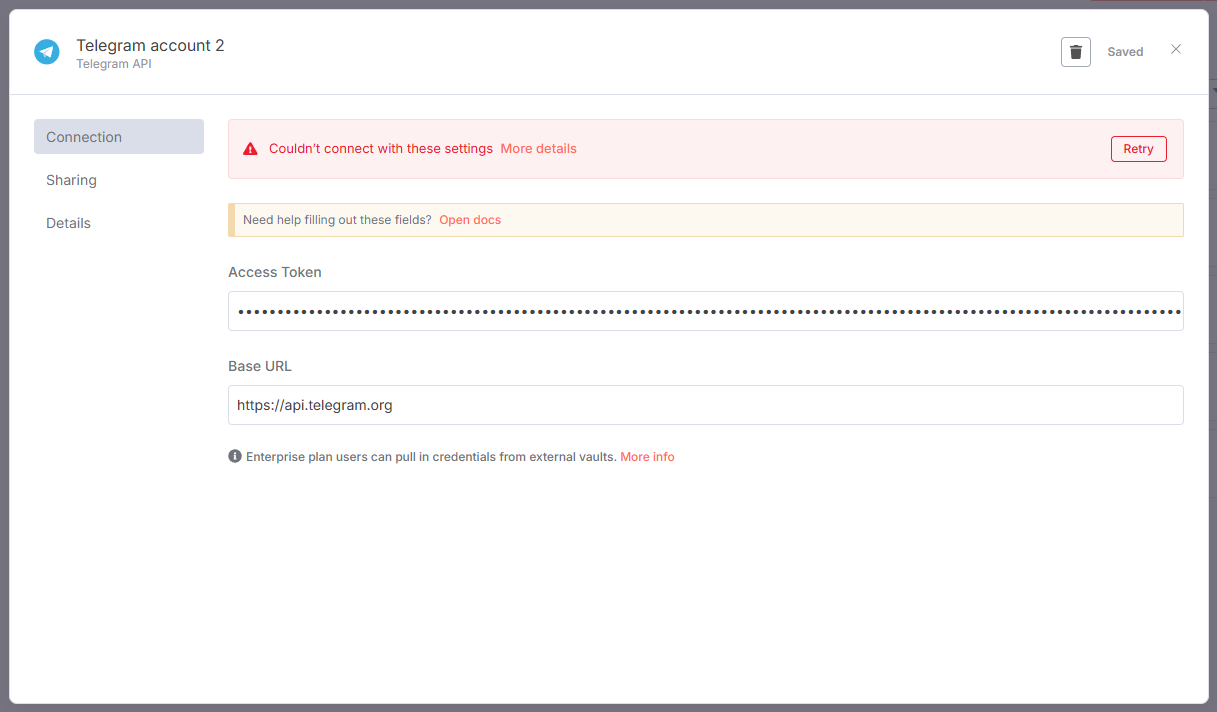
В случае ошибки сохранения токена — скопируйте токен из BotFather еще раз и попробуйте вставить его в поле Access Token.
После успешного сохранения токена его можно многократно использовать в разных workflow с разными Telegram-нодами.
Что уже получилось и что будет дальше?
Как мы и говорили в начале статьи — материал получился объемным и технически непростым. Уложиться в одну статью было просто невозможно. Поэтому эта статья была больше теоретической и подготовочной, а следующая статья будет более практической.
Подведем промежуточные итоги того, что мы узнали и что у нас уже получилось сделать:
- Детально разобрались в логике работы проекта и поняли, какие нужны ресурсы для запуска продакш-версии Telegram-бота.
- Собрали рабочий и стабильный стек продакш Telegram-бота, который запускается одной командой docker compose up -d. Код проекта лежит здесь.
- Создали Telegram-бота.
В следующей статье — детально разберемся в работе стека и workflow. Будем плотно работать с Docker и запустим в продакшн Telegram-бота. Если вы пока не знакомы с Docker или вы новичок, ознакомьтесь с нашим разделом по Docker в базе знаний. Также у нас в блоге есть полезная и интересная статья про локальный запуск LLM — тоже пригодится для большего понимания последующего материала.