AI сейчас повсюду, и стремление людей автоматизировать все, что только можно автоматизировать, выходит на новый уровень. В большей степени этому способствуют корпорации, которые разрабатывают большие языковые модели, или LLM. Доступ к проприетарным моделям, таким как GPT-4o, DeepSeek и Grok, ограничен возможностями подписок и ресурсами владельцев LLM, однако на помощь приходят открытые LLM, которые можно использовать локально.
В этой статье мы расскажем о том, как можно запустить LLM локально на VPS и что для этого потребуется. Будет все, что вы так любите: знакомство с технологиями и конкретными инструментами, пошаговые инструкции, Linux-команды и Docker compose конфигурации. Выбирайте наиболее удобный для вас сценарий установки окружения для работы с локальными LLM (ручная установка или автоматическая) и погружайтесь в мир AI чудес.
Что такое Ollama

Ollama — это универсальный open-source фреймворк для локального запуска и работы с LLM (большими языковыми моделями) на обычном «железе»: от мощных bare metal-серверов и VPS до ноутбуков, мини-ПК и одноплатных компьютеров. Ollama можно установить на Windows, macOS и Linux.
Ollama стала де-факто стандартом для локального запуска LLM благодаря тому, что с ее помощью можно:
- автоматически скачивать модели из официальной библиотеки Ollama и сторонних реестров;
- запускать модели как на GPU, так и на CPU, что особенно важно для владельцев VPS без графических ускорителей;
- эффективно управлять десятками моделей одновременно: обновлять, удалять, переименовывать, просматривать список;
- взаимодействовать с моделями через GUI, CLI, API;
- работать в Docker-контейнерах или в standalone-режиме.
Сейчас почти все крупные игроки мира LLM так или иначе стараются выпустить свои модели в open-source, чтобы как можно больше привлечь аудитории к своим решениям. Поэтому Ollama как open-source фреймворк имеет свою коллекцию открытых LLM, которые можно скачать и использовать локально.
Среди самых популярных моделей:
- DeepSeek-V3 – мощная открытая LLM для глубоких размышлений, программирования и работы с внешними инструментами. Ключевые особенности: вызов функций и инструментов, настраиваемая глубина рассуждений, цепочка мыслей, контекст до 128K токенов, высочайшая производительность в коде и математике среди открытых моделей 2025 года;
- GPT-4o – открытая LLM от OpenAI для сложного рассуждения, агентских задач и универсальной разработки. Ключевые особенности: вызов функций и веб-браузинг, полный доступ к цепочке мыслей, настраиваемая степень рассуждений, поддержка тонкой настройки, контекст до 128K токенов;
- Qwen3-vl – мультимодальная LLM (vision+language) для визуального рассуждения, работы с интерфейсами и видео, а также текстовых задач. Ключевые особенности: визуальные агенты, пространственное понимание (2D/3D-локализация), обработка видео, контекст до 1 млн токенов, улучшенное OCR на 32 языках, превосходное STEM- и математическое рассуждение.
Ollama работает с моделями, которые можно использовать для рассуждений и автоматизации, например, в n8n. Они не подходят для генерации изображений и видео, хотя Qwen3-vl и может анализировать изображения, но генерировать новые изображения он не может.
Требования к оборудованию
Ollama может запускать локальные LLM на GPU или CPU, что позволяет владельцам VPS без GPU полноценно работать с LLM и реализовывать сложные сценарии автоматизации, например, с помощью n8n. Запуск LLM на CPU – это ресурсоемкий процесс, поэтому важно знать, какой объем ресурсов потребуется.
Сама Ollama как среда запуска LLM потребляет очень мало ресурсов и может запуститься даже на самой слабой VPS (1 CPU, 2 GB RAM, 40 GB HDD), а вот LLM потребляет намного больше ресурсов. Понять примерный объём ресурсов и требования к системе можно исходя из следующей информации:
- OS: для запуска Ollama потребуется Ubuntu версии 22.04 или выше.
- CPU: минимум 4 ядра, которых будет достаточно для запуска самых простых моделей, которые можно использовать для несложных задач автоматизации. На 8 CPU-ядрах можно запускать модели со средним уровнем рассуждения, а на 16+ CPU-ядрах могут запускаться модели с высоким уровнем рассуждения уровня DeepSeek-R1.
- RAM: потребуется минимум 8 GB для запуска самых простых моделей. На 16 GB запустятся модели со средним уровнем рассуждения. Для моделей с высоким уровнем рассуждения потребуется от 24 GB RAM.
- Disk: для установки самой Ollama потребуется 4 GB, ещё минимум 20+ GB потребуется для хранения нескольких LLM среднего уровня рассуждения. LLM-модели могут занимать до 400 GB, но в среднем их размер колеблется от 5 GB и до 50 GB.
Тип диска и его пропускная способность важны только при первой загрузке LLM в память, далее вся нагрузка ложится на CPU и RAM, а диск не используется, поэтому для экономии можно выбрать VPS с HDD. Однако по умолчанию Ollama для экономии ресурсов периодически выгружает LLM из памяти, что приводит к длительному ожиданию ответа LLM при повторной загрузке модели в память, поэтому если LLM будет использоваться редко – стоит все же рассмотреть VPS с SSD для сокращения времени загрузки LLM в память.
Резюме: для запуска LLM среднего уровня рассуждения потребуется VPS с 8 CPU-ядрами, 16 GB RAM и 300 GB HDD, а для работы с моделями высокого уровня рассуждения и использования их в автоматизации (n8n) потребуется VPS c 16+ CPU-ядрами, 24 GB RAM и 500+ GB HDD/SSD.
Заказать VPS для работы с LLM любого уровня рассуждения можно на странице VPS/VDS.
Установка и запуск Ollama на VPS
По умолчанию Ollama не имеет графического интерфейса и взаимодействовать с моделями можно через CLI или по API. Мы покажем как можно установить Ollama глобально на VPS вместе с Open WebUI – Web GUI к Ollama, и как можно запустить Ollama и Open WebUI в Docker с помощью Docker compose.
Ручная установка Ollama и Open UI в систему
Установить Ollama можно с помощью команды curl -fsSL https://ollama.com/install.sh | sh. После установки выполните команду ollama, чтобы удостовериться в том, что Ollama была успешно установлена. Теперь можно перейти в репозиторий моделей Ollama и выбрать модель для работы, например, можно скачать модель gpt-oss (14 GB), установить её и сразу приступить к работе с помощью команды ollama run gpt-oss.
Знак «>>>» с мигающим курсором означает, что вы внутри среды исполнения модели и LLM готова принимать запросы (prompt):
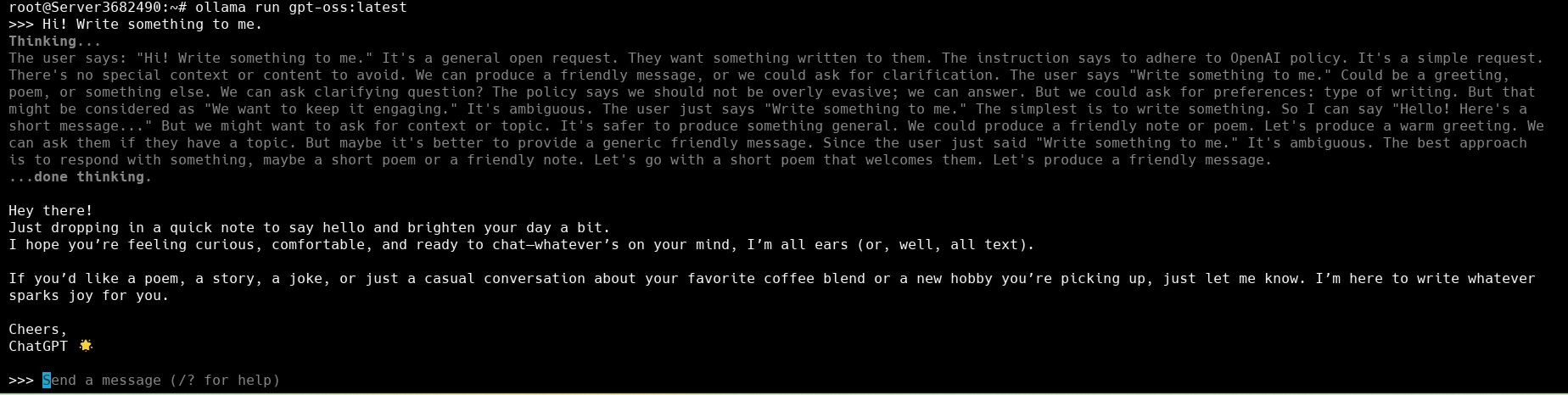
Чтобы выйти из строки запросов, введите команду /bye. Конечно, взаимодействовать с LLM через терминал не удобно, да и не нужно, когда есть более удобный и привычный интерфейс в виде чата. Для того чтобы запустить полноценный чат с Web GUI на базе Ollama, потребуется запустить Ollama в качестве сервера и подключить к нему Open UI.
Для запуска сервера Ollama выполните следующие шаги:
- Создайте пользователя и группу ollama:
sudo useradd -r -s /bin/false -U -m -d /usr/share/ollama ollama - Добавьте текущего пользователя в группу ollama:
sudo usermod -a -G ollama $(whoami) - Создайте сервис для systemd (/etc/systemd/system/ollama.service):
[Unit] Description=Ollama Service After=network-online.target [Service] ExecStart=/usr/bin/ollama serve User=ollama Group=ollama Restart=always RestartSec=3 Environment="PATH=$PATH" [Install] WantedBy=multi-user.target - Перезапустите службы systemd:
sudo systemctl daemon-reload - Сделайте сервис ollama доступным для запуска:
sudo systemctl enable ollama - Запустите сервис ollama:
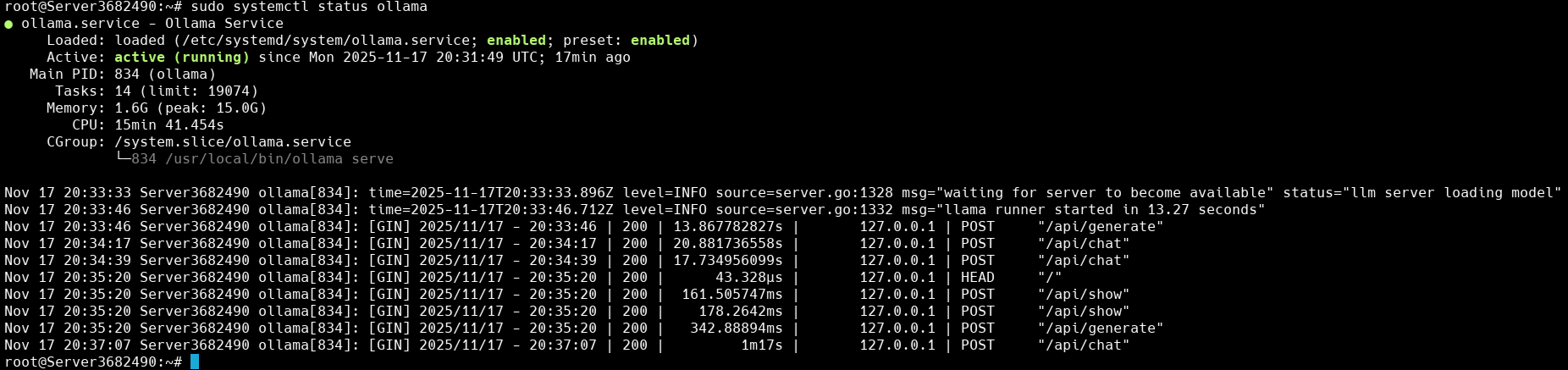
sudo systemctl start ollama - Проверьте статус сервиса ollama: sudo systemctl status ollama
При успешном запуске сервиса в терминал будет выведена системная информация о состоянии сервиса:
Теперь установим Open WebUI. Для этого создайте директорию webui в удобном для вас каталоге (mkdir webui), перейдите в созданную директорию, создайте виртуальное окружение Python командой python3 -m venv venv. Если venv у вас не установлен, установите его командой sudo apt install python3-venv.
Создадим сервис для Open webui, чтобы он сам стартовал при загрузке системы:
- Создайте конфигурационный файл сервиса Open WebUI:
sudo vim /etc/systemd/system/open-webui.service - Добавьте следующий код:
[Unit] Description=Open WebUI Service After=network.target [Service] Type=simple User=root Group=root WorkingDirectory=/root/webui Environment=PATH=/root/webui/venv/bin ExecStart=/root/webui/venv/bin/open-webui serve Restart=always RestartSec=5 [Install] WantedBy=multi-user.target - Перезапустите systemd:
sudo systemctl daemon-reload - Активируйте сервис Open WebUI:
sudo systemctl enable open-webui.service - Запустите сервис Open WebUI:
sudo systemctl start open-webui.service - Проверьте статус сервиса Open WebUI:
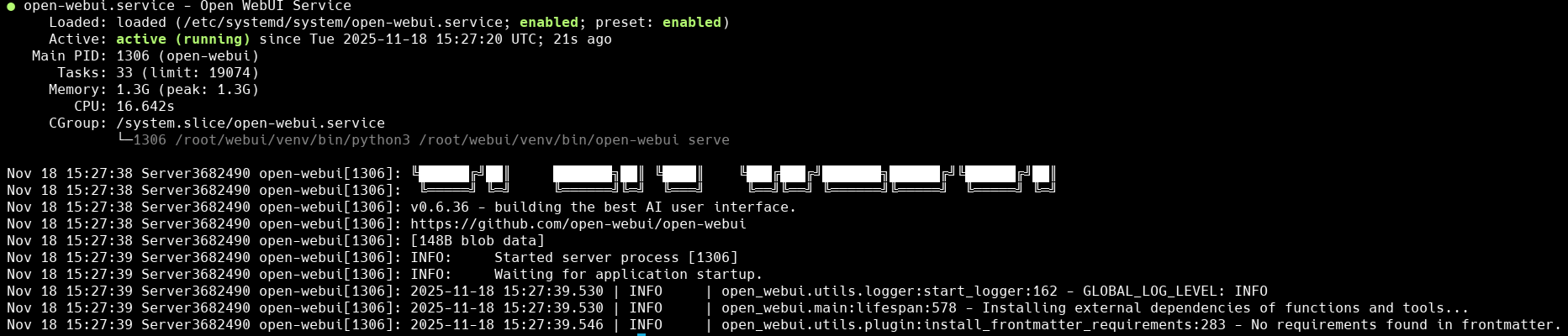
sudo systemctl status open-webui.service
При успешном запуске сервиса в терминал будет выведена следующая информация:
Теперь сервер доступен на порту 8080. Перейдите в браузер и введите в поисковую строку: ip_вашего_vps_сервера:8080. При первом запуске потребуется создать учетную запись администратора:

Далее откроется основная страница WebUI, где вы увидите, что WebUI автоматически подключился к созданному нам ранее серверу ollama:
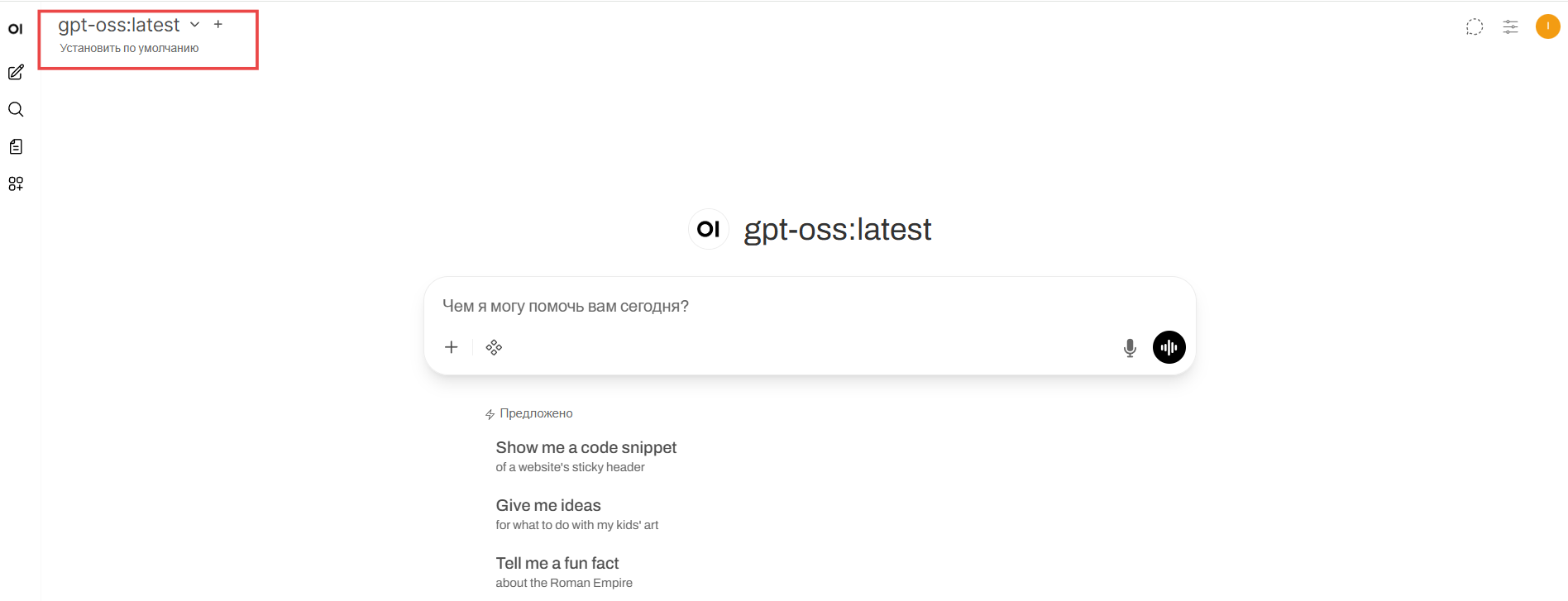
Первый запрос может выполняться долго из-за того, что модель будет загружаться в RAM, зато последующие запросы выполняются быстро.
Ручной способ установки Ollama и Open WebUI в систему не всегда удобен и оправдан только тогда, когда ваш VPS выполняет только одну задачу – хостинг и рендеринг LLM. В большинстве же случаев на VPS запущено множество процессов в Docker. Поэтому далее мы опишем способ развертывания связки Ollama и Open WebUI в Docker с помощью Docker Compose.
Запуск Ollama и Open WebUI в Docker

Если у вас не установлен Docker, воспользуйтесь следующей инструкцией:
- Добавьте GPG-ключи для скачивания Docker с помощью APT:
sudo apt update sudo apt install ca-certificates curl sudo install -m 0755 -d /etc/apt/keyrings sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc sudo chmod a+r /etc/apt/keyrings/docker.asc - Добавьте репозиторий Docker в APT:
sudo tee /etc/apt/sources.list.d/docker.sources < - Обновите APT:
sudo apt update - Установите последнюю версию Docker:
sudo apt install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin - Проверьте статус Docker:
sudo systemctl status docker
А если Docker у вас установлен, но не установлен Docker Compose, выполните следующие шаги:
- Обновите APT:
sudo apt-get update - Установите Docker Compose плагин:
sudo apt-get install docker-compose-plugin - Проверьте, что Docker Compose установился:
docker compose version
Теперь все готово для запуска Ollama и Open WebUI в Docker. Вы можете скачать готовый compose-файл из этого репозитория или скопировать код из сниппета ниже:
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
volumes:
- ollama_data:/root/.ollama
networks:
- ollama-network
ports:
- "11434:11434"
environment:
- OLLAMA_NUM_PARALLEL=2
- OLLAMA_MAX_LOADED_MODELS=2
- OLLAMA_MODELS=/root/.ollama/models
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
restart: unless-stopped
volumes:
- open-webui_data:/app/backend/data
depends_on:
- ollama
environment:
- OLLAMA_BASE_URL=http://ollama:11434
networks:
- ollama-network
ports:
- "8181:8080"
extra_hosts:
- host.docker.internal:host-gateway
volumes:
ollama_data:
open-webui_data:
networks:
ollama-network:
driver: bridge
Выполните команду docker compose up -d в директории с compose.yaml файлом. После скачивания образов и создания контейнеров проверьте статус поднятых контейнеров командой docker compose ps:

Обратите внимание, что Open WebUI теперь доступен на порту 8181, и чтобы перейти в Web GUI, нужно ввести в браузере: ip_вашего_vps:8181. После установки Ollama нужно скачать модель для работы. Сделать это проще всего в Web GUI. Кликните по строке поиска моделей в левом верхнем углу и введите название модели для скачивания, например, llava:
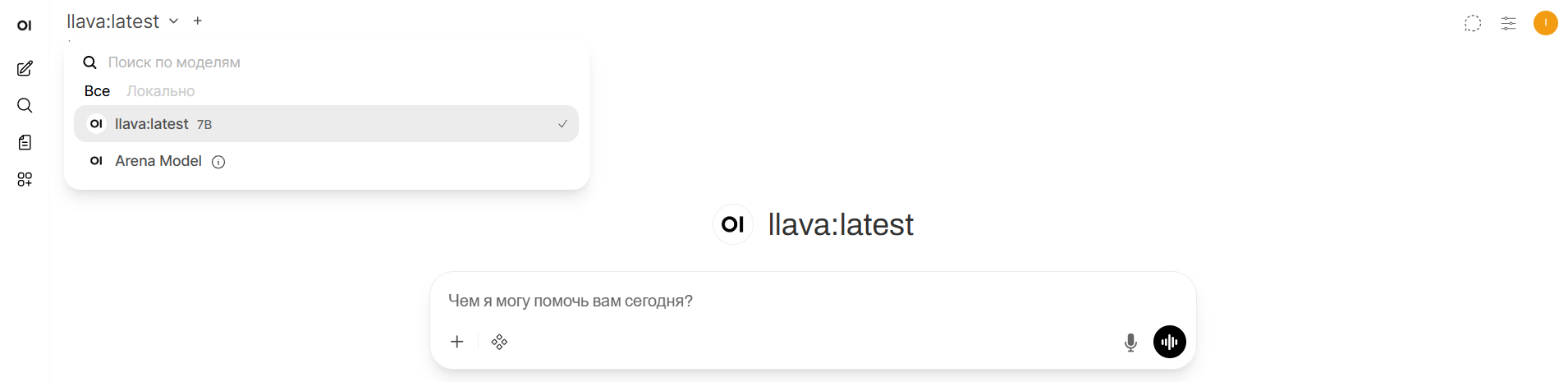
После того как модель скачается, она автоматически станет основной моделью для работы. Основное удобство развертывания Ollama и Open WebUI через Docker Compose в том, что можно с легкостью масштабировать количество сервисов, запущенных на VPS. Так в будущем вы можете добавить еще n8n для совместной работы с Ollama или ComfyUI для работы с визуальными моделями, при этом сервисы не будут конфликтовать друг с другом.
Резюме по установке и запуску Ollama на VPS
Сегодня мир AI развивается стремительно, а open-source стал еще одним полем борьбы корпораций за пальму первенства. Эта гонка технологий дает простым пользователям новые мощные инструменты, главным из которых являются открытые LLM.
Использование открытых LLM локально имеет ряд существенных преимуществ перед публичным доступом к проприетарным моделям:
- Не передается личная или NDA-информация на сторону владельца LLM
- Возможность подключения и настройки любого количества нужных вам инструментов
- Тонкая настройка LLM для работы с нужной вам информацией
- Точный контроль количества потребляемых ресурсов
Для локальной работы с открытыми LLM используются специальные фреймворки, такие как llama.cpp, LM Studio, vLLM, LocalAI, Text Generation WebUI (oobabooga), Ollama и другие фреймворки. Ollama получила наибольшее народное признание и популярность из-за того, что с ее помощью можно запускать LLM как на GPU, так и на CPU. Однако у Ollama есть и недостатки – она не имеет встроенного графического интерфейса. Нужно использовать сторонние решения, например, Open WebUI – открытый графический интерфейс для удобного взаимодействия с локальными LLM.
Кажется, что запуск такого сложного конвейера на VPS – это дорогостоящая и сложная задача, для которой потребуются особые технические знания и ресурсы. Однако сегодня существует множество открытых LLM, для запуска которых не требуется большого количества ресурсов. Например, для запуска LLM среднего уровня рассуждения потребуется VPS с 8 CPU-ядрами, 16 GB RAM и 300 GB SSD, а для работы с моделями высокого уровня рассуждения и использования их в автоматизации (n8n) потребуется VPS c 16+ CPU-ядрами, 24 GB RAM и 500+ GB HDD/SSD.
Начать открывать для себя преимущества работы с локальными LLM можно на VPS средней мощности (8 CPU, 16 GB RAM, 300 GB SSD), а далее можно перейти на более мощные конфигурации. В любом случае в разделе VPS/VDS вы сможете подобрать для себя оптимальную конфигурацию VPS для работы с локальными LLM.