Во второй части статьи мы детально разобрали работу бэкенда AI-чата на VPS. В этой финальной части статьи мы разберемся с тем, как работают удаленные GPU-инстансы, как они включаются в корпоративную инфраструктуру и при чем тут k8s и поды.
Для реализации AI-чата в качестве GPU-провайдера мы выбрали Runpod и будем на примере его сервисов показывать и объяснять концепции работы подов. Скажем сразу: можно выбрать любого другого GPU-провайдера, разница будет незначительная — почти все GPU-провайдеры работают по одному принципу.
Не будем тянуть и сразу перейдем к сути.
Что такое под у GPU-провайдеров
Термин «pod» (под) пришел из мира Kubernetes (k8s): там это минимальная единица развертывания, объединяющая контейнер и вычислительные ресурсы. У Runpod под играет аналогичную роль: это выделенный GPU- или CPU-инстанс с привязанными к нему ресурсами (vCPU, RAM, GPU и диски), внутри которого запускается один или несколько контейнеров. В отличие от Kubernetes, где ресурсы пода можно гибко настраивать, у Runpod vCPU и RAM выдаются фиксированного размера для выбранного типа пода и не могут быть изменены после создания, а вот количество подключенных видеокарт можно выбрать при создании пода.Отсутствие возможности тонкой настройки вычислительных ресурсов (vCPU, RAM и диски) может показаться стоп-фактором, но из приведенной ниже таблицы соотношения количества vCPU и RAM к GPU видно, что ресурсов более чем хватает для большинства AI-задач:
| Семейство | Тип GPU | Количество vCPU- ядер | Объем RAM | Количество GPU в POD |
| H | H200 SXM | 12 | 188 GB | 1–8 |
| H | H100 SXM | 20 | 188 GB | 1–8 |
| H | H100 PCIe | 31 | 176 GB | 1–8 |
| H | H100 NVL | 16 | 94 GB | 1–8 |
| H | NVIDIA H200 NVL | 16 | 283 GB | 1–8 |
| B | B200 | 24 | 180 GB | 1–6 |
| A | A40 | 9 | 48 GB | 1–8 |
| A | RTX A4000 | 5 | 25 GB | 1–8 |
| A | RTX A4500 | 12 | 62 GB | 1–8 |
| A | RTX A5000 | 9 | 25 GB | 1–8 |
| A | RTX A6000 | 8 | 50 GB | 1–8 |
| A | A100 PCIe | 12 | 117 GB | 1–8 |
| A | A100 SXM | 16 | 117 GB | 1–8 |
| L | L4 | 14 | 55 GB | 1–5 |
| L | L40 | 16 | 250 GB | 1–5 |
| L | L40S | 16 | 62 GB | 1–5 |
| RTX | RTX 5090 | 12 | 92 GB | 1–8 |
| RTX | RTX 2000 Ada | 6 | 15 GB | 1–8 |
| RTX | RTX 4000 Ada | 9 | 50 GB | 1–8 |
| RTX | RTX 4090 | 8 | 31 GB | 1–8 |
| RTX | RTX 6000 Ada | 16 | 62 GB | 1–8 |
| RTX | RTX PRO 6000 | 16 | 188 GB | 1–8 |
| RTX | RTX PRO 6000 WK | 16 | 188 GB | 1–8 |
| AMD | MI300X | 24 | 283 GB | 1–6 |
Расшифруем также названия семейств видеокарт и их назначения:
- H — Hopper, серверные GPU под обучение и компьютерное зрение
- B — Blackwell, топовые серверные GPU под LLM и тяжелый inference
- A — Ampere и A-серия, универсальные серверные GPU
- L — L-серия, энергоэффективные серверные GPU под инференс
- RTX — рабочие станции и игровые RTX
- AMD — Instinct, серверные GPU AMD
Итак, под — это выделенный инстанс с GPU/CPU-ресурсами, внутри которого работает контейнер с кодом и моделями. Очень важно понимать, как ведет себя под, чтобы правильно выбрать стратегию работы с подами. Вот некоторые важные свойства подов:
- Под создается или стартует после остановки за заметное время, так как впервые или заново разворачивается контейнер из образа.
- Файлы внутри пода при его остановке удаляются (если не подключен внешний диск для хранения данных) и не могут быть восстановлены.
- После создания пода нельзя изменить аллоцированные под него ресурсы.
Под — это удобная и современная единица построения инфраструктуры. Его можно использовать как основной инструмент и строительный блок инфраструктуры, а можно применять как вспомогательный удаленный ресурс. В концепции AI-чата мы используем поды именно как вспомогательный ресурс, а вся бизнес-логика находится на VPS.
Деплой подов из шаблонов
Runpod предлагает широкий выбор готовых шаблонов контейнеров, из которых можно быстро собрать под, подобрав нужный набор вычислительных ресурсов. В терминологии Runpod под — это выделенный GPU- или CPU-инстанс для запуска контейнеризованных AI/ML-нагрузок, а контейнер — Docker-среда с кодом, зависимостями и рантаймом, которая запускается внутри пода:
У Runpod шаблон — это конфигурация контейнера, где заданы все соответствующие параметры:
- Образ, из которого будет разворачиваться контейнер
- Порты и переменные окружения
- Параметры запуска процесса
Важно отметить, что шаблон — это всего лишь лекало, по которому будет создан под, а не готовый к работе под. Поэтому на деплой пода из шаблона, в зависимости от процесса, который будет запущен в контейнере, может уйти от нескольких секунд до 10 минут. Например, мы используем шаблон
Фишка шаблонов Runpod в том, что они содержат комбинации сред запуска LLM с разными моделями. Например, vLLM + Llama 3 / Qwen 3 / Deepseek, Ollama + Llama 3 / Qwen 3 / Deepseek, а также базовые среды вроде Runpod Pytorch (2.1, 2.2.0, 2.4.0, 2.8.0) для своих моделей и скриптов.
После создания пода становятся доступны следующие разделы его свойств:
- Порты для внешнего подключения к поду: рабочие порты процесса и SSH-порты
- Телеметрия: показатели утилизации вычислительных ресурсов пода: vCPU, RAM, vRAM, Disk, Volume
- Logs — логирование процесса сборки контейнера внутри пода
- Details — основная информация о поде: модель видеокарты, количество вычислительных ресурсов, URL образа, из которого собирается контейнер
Вот так под отражается в консоли после деплоя:

После деплоя пода его можно включать в инфраструктуру. Важно отметить, что аренда пода начинается с момента запуска процесса создания или разморозки пода, а не с момента начала его фактической полезной работы под нагрузкой.
Включение подов в инфраструктуру корпоративного контура
В нашем случае поды включаются в инфраструктуру по OpenAI совместимому API. liteLLM поднимает OpenAI совместимое API на VPS и по такому же OpenAI совместимому API ходит в vLLM, запущенный в подах на Runpod. Логическая схема работы инфраструктуры AI-чата выглядит так:
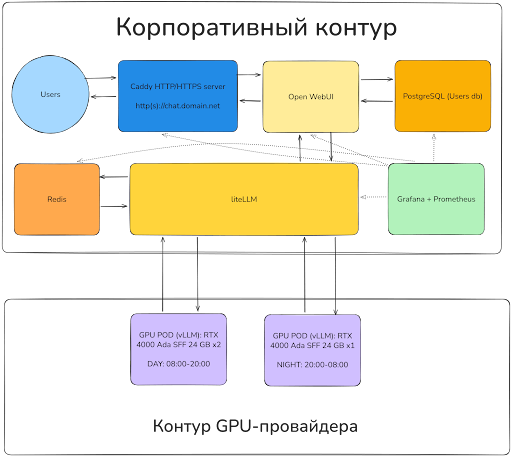
liteLLM проксирует запросы в vLLM по OpenAI совместимому API поверх HTTP/HTTPS. Такой подход включения подов в инфраструктуру имеет свои плюсы и минусы:
| Плюсы | Минусы |
| Не нужно настраивать сети | Запросы могут быть заблокированы провайдером, а пакеты могут теряться |
| Легко тестировать и дебажить на стороне VPS | Иногда логи пода не отражают проблемы и нужно заходить по SSH в под |
| Легко масштабировать | Можно запутаться в подах |
Настройки проксирования запросов в конфигурационном файле liteLLM выглядят так:
model_list:
- model_name: os.environ/MODEL_NAME
litellm_params:
model: os.environ/MODEL_PATH
api_base: os.environ/VLLM_API_BASE_1
api_key: os.environ/VLLM_API_KEY
num_retries: 3
timeout: 300
model_info:
id: vllm-pod1
- model_name: os.environ/MODEL_NAME
litellm_params:
model: os.environ/MODEL_PATH
api_base: os.environ/VLLM_API_BASE_2
api_key: os.environ/VLLM_API_KEY
num_retries: 3
timeout: 300
model_info:
id: vllm-pod2
Переменные окружения, которые указаны в конфигурационном файле, находятся в файле .env и имеют следующие значения:
MODEL_NAME=llama3-8b
MODEL_PATH=hosted_vllm/NousResearch/Meta-Llama-3-8B-Instruct
VLLM_API_BASE_1=https://9o1qrfpuwamaiv-8000.proxy.runpod.net/v1
VLLM_API_BASE_2=https://33pi69ozbz1sw5-8000.proxy.runpod.net/v1
VLLM_API_KEY=not-needed
Поскольку мы запускаем два идентичных пода с разным количеством видеокарт, то разными будут только API-эндпоинты, а все остальное одинаковое.
Заключение: корпоративный AI-чат от идеи до реализации
Мы прошли длинный путь: от верхнеуровневого описания бизнес-идеи и до финальной реализации проекта на собственной инфраструктуре — VPS и поды. Идея была в создании высоконагруженного корпоративного AI-чата (100+ одновременных запросов на VPS) в корпоративном контуре с использованием внешних GPU-инстансов. Запросы пользователей AI-чата и их данные должны оставаться на VPS внутри корпоративного контура, а стоимость аренды GPU не должна превышать 500 USD в месяц.
Более полный список требований к инфраструктуре AI-чата:
- Вся бизнес-логика корпоративного AI-чата располагается в корпоративном контуре на VPS
- Вычислительные GPU-мощности (поды) для работы AI располагаются на стороне GPU-провайдера
- Поды подключаются к корпоративной инфраструктуре по OpenAI совместимому API
- Стоимость VPS и подов рассчитывается по модели Pay-as-you-Go
- Количество подов можно масштабировать
Главная идея реализации текущего проекта AI-чата — отделение вычислительных GPU-мощностей от бизнес-логики и данных, которые остаются в закрытом корпоративном контуре на VPS, на котором запущены следующие сервисы:
- Open WebUI — open‑source Web UI, принимающий запросы от пользователей через поддомен chat.domain.online
- LiteLLM — proxy‑сервер к среде запуска vLLM, который передает запросы в GPU‑инстансы на стороне GPU‑провайдера
- Redis — in‑memory СУБД, в которой мы храним кеш LiteLLM для ускорения ответов и экономии токенов
- PostgreSQL — СУБД для хранения SQL‑данных, в которой мы храним учетные записи пользователей Open WebUI
- Caddy — HTTP/HTTPS‑сервер, который обрабатывает все входящие HTTP/HTTPS‑запросы на домен и поддомены
- Grafana + Prometheus — связка двух сервисов для сбора метрик и построения отчетов
В подах запущены vLLM — по одному экземпляру на под. Мы используем поды разной мощности: Под-1 — RTX 4000 Ada SFF 24 GB vRAM x1 и Под-2 — RTX 4000 Ada SFF 24 GB vRAM x2. Подобная комбинация позволяет нам гибко масштабировать кластер подов по следующей схеме: во время высоких нагрузок (с 8:00 до 20:00) — работают два пода, а вечером и ночью — только Под-1.
Расходы на содержание двух подов:
- Под-1: RTX 4000 Ada SFF 24 GB vRAM x1, работает круглосуточно, стоимость 0,20 USD в час, 144 USD в месяц
- Под-2: RTX 4000 Ada SFF 24 GB vRAM x2, работает с 08:00 до 20:00, стоимость 0,40 USD в час, 144 USD в месяц
Итог: 288 USD в месяц за два пода, способные обеспечить запуск моделей уровня Llama3 8B для сотни пользователей. Скачать compose-файлы для запуска и конфигурирования AI-чата на ВМ можно из этого репозитория, а надежный и бюджетный VPS для развертывания проекта — в разделе VPS/VDS.