В первой части цикла мы рассмотрели верхнеуровневую логику работы AI‑чата и рассказали о его возможностях и ресурсах, которые нужны для его запуска и явном профите, который он приносит. В этой части — мы погрузимся в технические детали реализации бэкенда AI‑чата на VPS.
Будет много кода, YAML‑синтаксиса и логики работы Docker‑контейнеров. Напомним, что код проекта можно скачать из этого репозитория, а VPS, на котором можно попробовать проект, можно заказать тут — в разделе VPS/VDS. GPU‑инстансы заказываются у любого GPU‑провайдера. Мы использовали Runpod GPU‑инстансы.
Сердце AI‑чата — GPU‑инстансы, на которых происходят все расчеты, а мозг AI‑чата — VPS, на котором запущены все сервисы. Такой подход дает важное преимущество — все данные остаются в корпоративном контуре. На GPU‑инстансах данные удаляются каждые 12 часов из‑за перезапуска контейнеров, поэтому об утечке NDA‑информации можно не беспокоиться.
Сервисы, запущенные на VPS:
- Open WebUI — open‑source Web UI, принимающий запросы от пользователей через поддомен chat.domain.online
- LiteLLM — proxy‑сервер к среде запуска vLLM, который передает запросы в GPU‑инстансы на стороне GPU‑провайдера
- LiteLLM — proxy‑сервер к среде запуска vLLM, который передает запросы в GPU‑инстансы на стороне GPU‑провайдера
- Redis — in‑memory СУБД, в которой мы храним кеш LiteLLM для ускорения ответов и экономии токенов
- PostgreSQL — СУБД для хранения SQL‑данных, в которой мы храним учетные записи пользователей Open WebUI
- Grafana + Prometheus — связка двух сервисов для сбора метрик и построения отчетов
Графически стек, запущенный на VPS, можно представить так:
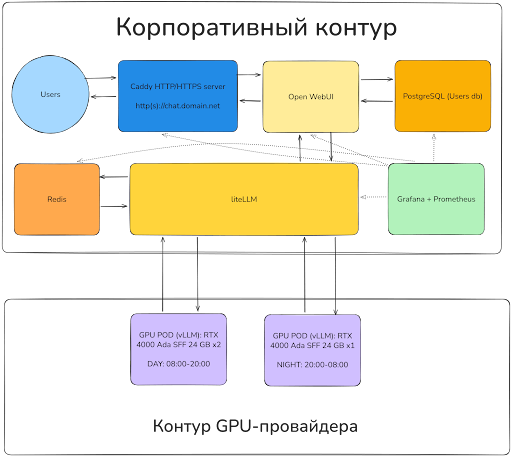
Разберем детально каждый сервис, опишем его свойства и некоторые тонкости настройки.
Open WebUI
Open WebUI — это open‑source Web UI, который работает по API со средами запуска LLM (Ollama, vLLM). Open WebUI управляет пользователями, чатами и выбором LLM‑модели. Контейнер поднят на порту 8080. Код сервиса находится тут.
Из коробки Open WebUI настроен для максимально простого и бесконтрольного доступа к средам запуска LLM. В нашем стеке выставлены следующие параметры безопасности и контроля доступа:- OPENAI_API_KEY — ключ доступа к OpenAI‑совместимому API. Пример: OPENAI_API_KEY=sk-1234. Для нескольких ключей используется OPENAI_API_KEYS (значения ключей перечисляются через ;). Пример: OPENAI_API_KEYS=sk-1234;sk-456.
- ENABLE_SIGNUP — разрешает регистрацию пользователей. Значения: true/false. Выставлено: true. Стратегия работы с опцией следующая: при первом старте сервиса ENABLE_SIGNUP выставляется в true и через Open WebUI регистрируется администратор, затем опция выставляется в false и контейнер перезапускается. Дальше пользователи добавляются администратором в БД, а возможность регистрации пользователей в Open WebUI закрыта.
- WEBUI_SECRET_KEY — секрет для JWT и шифрования. Опция нужна для аутентификации сессий и сохранения истории чатов. Задается вручную. Пример: WEBUI_SECRET_KEY=jwt17b56.
- DEFAULT_USER_ROLE — роль по умолчанию для новых пользователей (pending, user, admin). Первому регистрирующемуся автоматически назначается роль admin, а остальным user, если регистрация открыта. Пример: DEFAULT_USER_ROLE=user.
- WEBUI_AUTH — включает аутентификацию по почте и паролю. По умолчанию true. Значение выставлено в true. Пример: WEBUI_AUTH=true.
Для большей гибкости управления учетными записями пользователей они вынесены в отдельную БД PostgreSQL, а в Open WebUI заданы следующие опции работы с внешней БД:
- DATABASE_URL — полный URL подключения к базе данных, где хранятся учетные записи пользователей и история их чатов. Используется как SQLite, так и PostgreSQL. Пример для PostgreSQL: DATABASE_URL=postgresql://${POSTGRES_USER}:${POSTGRES_PASSWORD}@postgres-users:5432/${POSTGRES_DB}.
Запросы пользователей Open WebUI транслирует по OpenAI совместимому API для обработки в liteLLM — прокси‑сервер к vLLM, который запущен в поде на стороне GPU‑провайдера. В Open WebUI выставлены следующие настройки API:
- OPENAI_API_BASE_URL — базовый URL OpenAI совместимого API. Для liteLLM‑прокси указывается адрес вида http://
: /v1. Пример: OPENAI_API_BASE_URL=http://litellm-1:4000/v1. Поддерживается список из множества URLs через OPENAI_API_BASE_URLS (URLы разделяются ;). Пример: OPENAI_API_BASE_URLS=http://litellm-1:4000/v1;http://litellm-2:4000/v1.Это удобно для балансировки, если есть высоконагруженный Open WebUI и нужно несколько OpenAI совместимых API. - OPENAI_API_KEY — ключ доступа к OpenAI совместимому API. Пример: OPENAI_API_KEY=sk-1234. Для нескольких ключей используется OPENAI_API_KEYS (значения ключей перечисляются через ;). Пример: OPENAI_API_KEYS=sk-1234;sk-456
liteLLM
liteLLM — это proxy‑сервер к средам запуска LLM (vLLM, Ollama, LM Studio, Xinference, Llamafile и другие). В нашем стеке liteLLM проксирует запросы в vLLM, который запущен на подах.
Контейнер с LiteLLM можно сконфигурировать через переменные окружения и с помощью конфигурационного файла в YAML‑формате. В нашем случае сервис сконфигурирован и через конфигурационный файл, и через переменные окружения. Мы используем два GPU‑инстанса, к которым подключаемся по одному API‑ключу.
В конфигурации такой подход выглядит так:
- VLLM_API_BASE_1 — URL первого GPU‑инстанса: ${VLLM_API_BASE_1}(https://9o1qrfpuwamaiv-8000.proxy.runpod.net/v1)
- VLLM_API_BASE_2 — URL второго GPU‑инстанса: ${VLLM_API_BASE_2}(https://33pi69ozbz1sw5-8000.proxy.runpod.net/v1)
- VLLM_API_KEY — API‑ключ для подключения к vLLM: ${VLVLLM_API_KEY(some_key))
Переменные окружения пробрасываются внутрь контейнера liteLLM и используются в конфигурационном файле следующим образом:
model_list:
- model_name: os.environ/MODEL_NAME
litellm_params:
model: os.environ/MODEL_PATH
api_base: os.environ/VLLM_API_BASE_1
api_key: os.environ/VLLM_API_KEY
num_retries: 3
timeout: 300
weight: 1
model_info:
id: vllm-pod1
- model_name: os.environ/MODEL_NAME
litellm_params:
model: os.environ/MODEL_PATH
api_base: os.environ/VLLM_API_BASE_2
api_key: os.environ/VLLM_API_KEY
num_retries: 3
timeout: 300
weight: 2
model_info:
id: vllm-pod2
Опции num_retries и timeout не проброшены переменными из‑за того, что они числовые, а переменные окружения приходят внутрь контейнера в формате строк. Главное, на что нужно обратить внимание — это то, что model_name одинаковый в секции model_list. Именно благодаря этому работает балансировка между GPU‑инстансами.
Также важный раздел в конфигурационном файле — это router_settings, он задает поведение liteLLM при работе с упавшими GPU‑инстансами:
router_settings:
routing_strategy: simple-shuffle
num_retries: 3
timeout: 300
allowed_fails: 3 # Больше попыток перед отключением
cooldown_time: 60 # Реже проверяем недоступные поды
enable_pre_call_checks: true
retry_after: 10 # Больше времени между retry
При приведенной конфигурации liteLLM будет повторять каждый запрос к GPU‑инстансу до 3 раз при ошибке (num_retries: 3), причем повторы происходят мгновенно, без задержки. После того как 3 запроса подряд провалятся (каждый уже с учетом retry), GPU‑инстанс будет помечен как недоступный (allowed_fails: 3) и исключен из ротации на 60 секунд (cooldown_time: 60), в течение которых все запросы будут направляться только на другие доступные инстансы. По истечении 60 секунд liteLLM снова начнет пробовать обращаться к упавшему GPU‑инстансу.
Такая стратегия позволяет реализовать сразу два механизма:
- Балансировка при возникновении сетевых проблем с GPU‑инстансами
- Выключение/подключение GPU‑инстанса в зависимости от нагрузки
Еще liteLLM умеет кешировать ответы vLLM. Для большего удобства управления ресурсами мы вынесли кеш liteLLM в отдельный Redis‑сервис — redis-cache, про который поговорим отдельно, а пока приведем блок настроек liteLLM для кеширования:
litellm_settings:
cache: True
cache_params:
type: redis
host: os.environ/REDIS_HOST
port: os.environ/REDIS_PORT
ttl: os.environ/REDIS_CACHE_TTL
namespace: os.environ/REDIS_CACHE_NAMESPACE
Тут важно отметить, что ttl задает время хранения кеша в секундах. Мы выставили значение 2592000, что соответствует 30 дням, после этого кеш будет сброшен. TTL подбирается индивидуально под ресурсы VPS, на котором он запущен.
Redis
Redis — in‑memory СУБД для хранения данных в памяти. Данные из Redis извлекаются и записываются очень быстро, поэтому Redis часто используют как кеш‑хранилище. В нашем стеке он хранит кеш ответов vLLM: liteLLM при получении запроса сначала обращается к Redis за контекстом ответа, а затем — к vLLM.
Благодаря использованию кеша сильно сокращается время ответа и нагрузка на LLM, так как тратится меньше токенов. Время хранения кеша задается в конфигурационном файле LiteLLM, а объемы выделенных ресурсов для хранения кеша — в compose‑файле Redis с помощью переменной окружения ${REDIS_MAX_MEMORY}:
redis-cache:
...
command: redis-server --maxmemory ${REDIS_MAX_MEMORY}
--maxmemory-policy ${REDIS_EVICTION_POLICY}
...
Подход разделения времени хранения данных (ttl) и выделения нужного объема памяти под хранение ${REDIS_MAX_MEMORY} позволяет более гибко управлять сервисом и выносить его, например, на отдельную ВМ.
Caddy
Caddy — HTTP/HTTPS‑сервер и обратный прокси‑сервер с TLS‑шифрованием. У Caddy несколько сильных сторон:
- Встроенный клиент Let’s Encrypt, который сам выдает TLS‑сертификаты и обновляет их
- Синтаксис конфигурационного файла Caddy сильно проще и удобнее, чем у NGINX
В нашем стеке Caddy используется как reverse‑proxy‑сервер с автоматическим SSL/TLS и обрабатывает запросы на поддомене chat.some_domain.com, на котором проксирует запросы к Open WebUI (корпоративный чат) на порт 8080 с настройками для долгих LLM‑запросов (таймауты до 5 минут).
Конечно, вместо Caddy можно использовать NGINX, но нам больше нравится Caddy из-за его простоты и функциональности из коробки.
PostgreSQL
PostgreSQL — СУБД для хранения SQL‑данных. В нашем стеке в PostgreSQL мы храним учетные записи пользователей Open WebUI и их чаты. Это удобно для администрирования: администратор добавляет пользователя в БД и выдает доступы лично — так все под контролем.
Сервис настраивается очень просто:
services:
postgres-users:
image: postgres:16-alpine
container_name: postgres-users
restart: unless-stopped
environment:
- POSTGRES_DB=${POSTGRES_DB}
- POSTGRES_USER=${POSTGRES_USER}
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD}
volumes:
- postgres_users_data:/var/lib/postgresql/data
networks:
- internal
healthcheck:
test: ["CMD-SHELL", "pg_isready -U openwebui"]
interval: 10s
timeout: 5s
retries: 5
Open WebUI для работы с внешними базами данных использует Alembic и SQLAlchemy. Поэтому ничего настраивать, кроме POSTGRES_DB, POSTGRES_USER и POSTGRES_PASSWORD, не нужно.
Monitoring
Grafana + Prometheus — классическая система сбора метрик и графическое представление метрик в виде графиков. В нашем стеке мы собираем следующие метрики:
- vLLM (GPU‑инстансы):
- Time To First Token (TTFT) — время до первого токена (средние значения, p50, p90, p99)
- End‑to‑End (E2E) Request Latency — полная задержка запроса от начала до конца (средние значения, перцентили)
- Количество запущенных и ожидающих запросов (num_requests_running, num_requests_waiting)
- Утилизация GPU cache (gpu_cache_usage_perc)
- Количество обработанных промпт‑токенов и сгенерированных токенов
- Успешные/неуспешные запросы
- liteLLM (прокси‑сервер):
- Общее количество запросов (litellm_requests_total)
- Длительность обработки запросов (litellm_request_duration_seconds)
- Задержка API‑вызовов к LLM (litellm_llm_api_latency_seconds)
- Cache hit/miss rate — эффективность кеширования
- Метрики по deployment (pod1/pod2)
- Redis (кеш LLM‑ответов):
- Использование памяти (used/max bytes, процент загрузки)
- Количество ключей в базе (всего, с TTL, без TTL)
- Cache hits/misses rate — попадания/промахи кеша
- Скорость выполнения команд по типам (GET, SET, DEL и т. д.)
- Среднее время выполнения команд
- Network I/O (входящий/исходящий трафик)
- Количество подключенных клиентов
- Evicted/expired keys — вытесненные и истекшие ключи
- Системные метрики (через cAdvisor):
- Утилизация CPU и памяти контейнеров
- Network I/O контейнеров
- Disk I/O
- Caddy (reverse‑proxy):
- HTTP‑метрики запросов и ответов
- Статусы сертификатов TLS
- Open WebUI:
- Health check статус приложения
Мы измеряем все необходимые показатели для четкого понимания загруженности сервисов и ресурсов. Если один из сервисов начнет “захлебываться” из‑за большой нагрузки — это будет сразу видно. “Расшить” узкое место инфраструктуры можно будет масштабированием.
Потенциал к масштабируемости
Сейчас весь стек крутится на одном VPS малой мощности: 8 CPU‑ядер, 16 GB RAM, 200 GB SSD. Такой конфигурации с лихвой хватает для обслуживания 20‑30 одновременных запросов к LLM. Для обслуживания 40‑50 одновременных запросов потребуется увеличить количество ядер на +2‑4 и оперативной памяти на 8+ GB.
Есть две стратегии масштабирования сервисов:
- Увеличивать количество процессов в контейнерах Open WebUI и LiteLLM
- Создавать кластеры из однопроцессных инстансов Open WebUI и LiteLLM
Выбор стратегии индивидуален и зависит от ресурсов. Конечно же, наилучшим вариантом будет K8s‑кластер для всего стека, но на старте сгодится и одна VPS средней мощности.
Кратко о бэкенде AI‑чата на VPS
На VPS запущены все сервисы AI‑чата за исключением vLLM: он запущен в поде на стороне GPU‑провайдера. Такая архитектура бэкенда позволяет держать все под контролем — запросы пользователей, персональные данные и вся статистика хранятся на VPS, а поды только обрабатывают запросы с периодической очисткой данных.
Бэкенд AI‑чата на VPS — это связка из трех основных сервисов:
- Caddy (HTTP/HTTPS‑сервер, Reverse proxy) — обрабатывает все входящие HTTP/HTTPS‑запросы на домен и поддомены
- Open WebUI (open‑source Web UI) — принимает запросы от пользователей и транслирует их в liteLLM
- liteLLM (proxy‑сервер к средам запуска LLM) — передает запросы в GPU‑инстансы на стороне GPU‑провайдера
Другие сервисы — вспомогательные, они нужны для лучшего масштабирования и более гибкого управления ресурсами и безопасностью. Среди вспомогательных сервисов:
- Redis — in‑memory СУБД, в которой мы храним кеш LiteLLM для ускорения ответов и экономии токенов
- PostgreSQL — СУБД для хранения SQL‑данных, в которой мы храним учетные записи пользователей Open WebUI
- Grafana + Prometheus — связка двух сервисов для сбора метрик и построения отчетов
Сервисы на VPS под нагрузкой потребляют незначительное количество ресурсов. Для одновременной работы 100+ пользователей будет достаточно VPS с 4 CPU‑ядрами, 8 GB RAM и 150 GB SSD. Схема разделенных ресурсов между VPS и GPU‑инстансами дает три важных преимущества:
- Независимое масштабирование сервисов на VPS и GPU‑инстансов
- Частичная или полная замена GPU‑провайдера без остановки сервисов и потери данных
- Сохранность NDA‑информации и тонкий контроль ресурсов и сервисов в корпоративном контуре
Подчеркнем еще раз мысль о том, что мы используем удаленные GPU‑инстансы лишь для запуска LLM, а весь стек с данными у нас запущен внутри корпоративного контура на VPS.